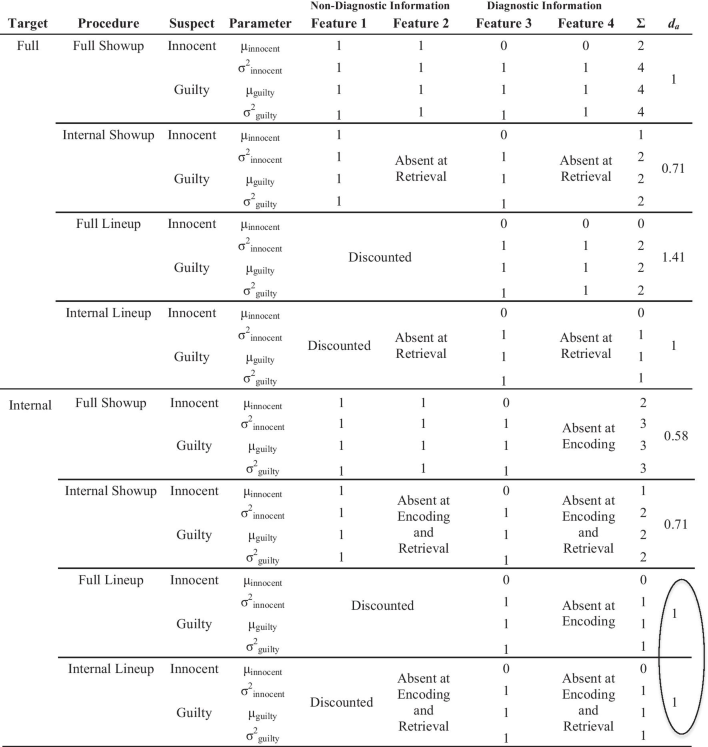
- Features 1 and 3 come from the internal face region and Features 2 and 4 come from the external face region. For simplicity, Discounted means that a Feature is completely eliminated from consideration, which assumes optimal decision-making. This is not an inherent assumption of DFT (because people are not perfectly optimal), but we apply it here for illustrative purposes. Most of these simple effects (i.e., discriminability comparisons in the right column) come from encoding specificity, with conditions that match encoding with retrieval being superior to mismatch conditions. However, the two circled discriminability values represent an important DFT prediction. They do not need to be equal, and Full Lineup could actually have somewhat lower discriminability due to adding noise (i.e., the external region of the face; e.g., Leder and Carbon 2005), but the difference between Internal-Full and Internal-Internal Lineup should be less than the difference between Internal-Full and Internal-Internal Showup. Both should be in the direction predicted by encoding specificity (i.e., Internal-Internal > Internal-Full), but for lineups, DFT predicts that eyewitnesses will notice shared qualities of these added features (e.g., they all have short dark hair) and therefore will discount these features to an extent not possible for a showup. This boosts discriminability for Full Lineups, but not Full Showups, thereby bringing the Internal-Full Lineup discriminability closer to Internal-Internal Lineup
